人工智能7项关键技术,终于有人懂了

指南:企业使用AI的一个复杂因素是,这个主题包含多个底层技术。 这些技术中的大多数可以执行许多替代功能。 技术和功能的结合非常复杂,表1-1列出了七个关键技术,包括每个关键技术的简要描述,以及它们可以实现的一些典型功能或应用程序。 表1-1人类智力。 指南:企业使用AI的一个复杂因素是,这个主题包含多个底层技术。 这些技术中的大多数可以执行许多替代功能。 技术和功能的结合非常复杂,表1-1列出了七个关键技术,包括每个关键技术的简要描述,以及它们可以实现的一些典型功能或应用程序。
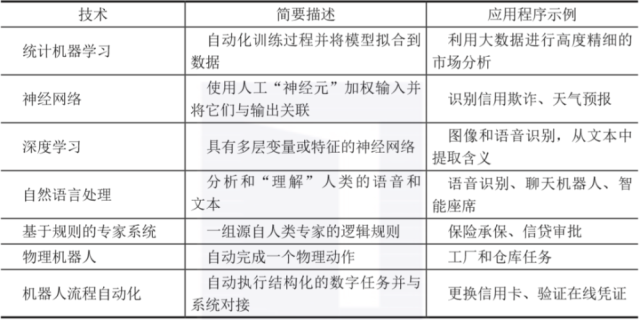
表1-1人工智能关键技术

本文更深入地描述了每种技术及其功能。我还将讨论每种技术在商业AI世界中是多么常见。 我的工作是商学院教授(与许多不同的公司合作),但我也是德勤战略和分析实践部门的高级顾问,该部门集人工智能咨询为一体。

以下是对每种技术及其功能的深入描述。

托马斯·达文波特(托马斯·达文波特)

资料来源:大数据DT(ID:hzdashujuju)

01~03统计机器学习、神经网络与深度学习
机器学习是一种将模型与数据自动匹配,并通过训练模型对数据进行“学习”的技术。 机器学习是人工智能最常见的形式之一。
德勤接触了250名经理(他们的公司已经在2017年探索AI)“了解认知”调查显示,58%的被调查公司在其业务中使用机器学习。 它是许多人工智能方法的核心技术,有许多版本。 内部和外部数据的爆炸性增长,特别是这些外部数据,使他们使用机器学习来充分理解这些数据是可行的和必要的。
神经网络是一种更复杂的机器学习形式,出现在20世纪60年代,并用于分类应用,如确定信贷交易是否欺诈。 它分析基于输入、输出、可变权重或“特征”将输入与输出关联起来的问题。 它类似于神经元处理信号的方式,但将其与大脑进行比较有点牵强。
最复杂的机器学习形式将涉及深度学习,或通过许多层次的特征和变量预测结果的神经网络模型。由于当前计算机体系结构的处理速度更快,这些模型能够应对数千个特性。
与早期的统计分析形式不同,深度学习模型中的每个特征通常对人类观察者没有什么意义。 结果是模型难以使用或难以解释。 只有34%的德勤调查使用了深度学习技术。
深度学习模型使用一种称为反向传播的技术来预测或分类输出通过模型。 人工智能技术推动了该领域的许多最新进展,从在围棋比赛中击败人类专家到对互联网图像进行分类,使用反向传播进行深度学习。 杰弗里辛顿(GeoffreyHinton),在多伦多大学和谷歌工作,经常被称为深度学习之父,部分原因是他早期的反向传播。机器学习使用了数百种可能的算法,其中大多数算法有点深奥。 它们的范围从梯度增强(一种建立用于解决先前模型错误的模型的方法,从而增强预测或分类能力)到随机森林(模型作为一组决策树模型)。
越来越多的软件工具(包括数据机器人、SAS和Google的AutoML)支持自动构建机器学习模型,可以尝试许多不同的算法来找到最成功的算法。 一旦通过训练数据找到可以预测或分类的最佳模型,就可以部署它,并可以预测或分类新的数据(有时称为评分过程)。
除了使用的算法外,机器学习的另一个关键是模型如何学习。 监督学习模型(到目前为止,商业中最常用的类型)是使用一组标记为输出的培训数据进行学习。
例如,试图预测银行欺诈的机器学习模型需要对显然构成欺诈案件的系统进行培训。 这是不容易做到的,因为实际欺诈的频率可能只有十万(有时被称为不平衡分类问题)。
监督学习与传统的分析方法(如回归分析)在评分模型中的应用非常相似。 在回归分析中,目标是创建一个模型,该模型使用与输出相关的一组输入变量,并且其值已知以预测已知结果。 一旦模型开发完成,就可以用同一输入变量的已知值来预测未知结果。
例如,根据患者的年龄、体力活动水平、卡路里消耗和体重指数,我们可以建立回归模型来预测他患糖尿病的可能性。
我们为糖尿病患者或非糖尿病患者建立模型(通常使用所有可用数据来建立回归模型)。 一旦找到合适的预测回归模型,它就可以根据一组新的数据(输入变量达到特定水平的患者的糖尿病可能性)来预测未知的结果)。 后续活动(在回归分析和机器学习中)称为评分。
回归过程与监督机器学习相同,但:
在机器学习中,用于开发(训练)模型的数据称为训练数据,它可以是为训练目的显式保留的数据子集;
在机器学习中,通常使用另一个数据子集来验证训练模型,并已知该子集的预测结果;
在回归中,可能不需要使用模型来预测未知的结果,但在机器学习中,结果将被假定;
许多不同的算法类型可以用于机器学习,而不是简单的回归分析。
通常很难开发无监督的模型来检测模式并预测未标记数据中的未知结果。
强化学习是第三种变体,这意味着机器学习系统为每一步目标设定目标并获得某种形式的奖励。 它在玩游戏中非常有用,但它也需要大量的数据(在许多情况下,太多的数据对方法不起作用)。
应该注意的是,有监督的机器学习模型通常不会继续学习。 他们从一组训练数据中学习,然后继续使用相同的模型,除非使用一组新的训练数据来训练新的模型。
机器学习模型是基于统计的,应该与常规分析进行比较,以阐明其价值增量。 它们通常比基于人类假设和回归分析的传统“手动”分析模型更准确,但也更复杂和难以解释。 自动化机器学习模型比传统的统计分析更容易创建和揭示更多的数据细节。
考虑到学习所需的数据量,深度学习模型在图像和语音识别等任务中是很好的(远远优于以前对这些任务的自动化方法,并且在某些领域接近或超过人类的能力)。
04自然语言处理
自20世纪50年代以来,理解人类语言一直是人工智能研究人员的目标。 这个领域被称为自然语言处理(自然语言处理,NLP),包括语音识别、文本分析、翻译、生成应用程序和其他与语言相关的目标。
在了解认知和调查中,53%使用NLP。 统计NLP有两种基本方法:统计NLP和语义NLP。2统计NLP基于机器学习,比语义NLP执行得更快。 在性能方面,需要一个大的和ldquo;语料库和rdquo;或语言系统来学习。
例如,它需要大量的翻译文本,统计分析表明,西班牙语和葡萄牙语中的Amor在统计上与英语中的love一词高度相关。 这有点像蛮力,但通常很有效。
语义NLP是近十年来唯一现实的选择。 如果系统能够有效地训练单词、语法和概念之间的关系,它将是相当有效的。
语言训练和知识工程(通常是为特定领域创建的知识图谱)可能会消耗大量的人力和时间。 然而,它需要开发一个知识主题的模型或单词和短语之间的关系。 虽然很难创建语义NLP模型,但一些智能座椅系统已经在使用这种方法。
NL应以两种方式衡量P系统性能。 一是看它能听懂多少%的口语。 随着深度学习技术的发展,该指标不断提高,往往超过95%。
衡量NLP的另一种方法是看看它能回答多少种不同类型的问题,或者它能解决多少问题。 语义通常需要NLP,但由于在这一领域没有重大的技术突破,Q&A和问题解决系统都是特定于上下文的,必须进行培训。
IBM watson在回答“危险边缘”问题方面做得很好,它不能回答“命运之轮”问题(财富之轮,综艺节目),除非它经过训练,通常是以劳动密集型的方式。 也许未来的深度学习将应用于解决问题,但它还没有。
基于规则的专家系统
在20世纪80年代,人工智能的主导技术是一个基于一套“if-then”规则的专家系统,当时它开始广泛应用于商业中。 今天,人们通常认为它不太先进,但2017年德勤(Deloitte“Cognitive”)的研究表明,49%的引入人工智能的美国公司使用了该技术。
专家系统要求人类专家和知识工程师在特定的知识领域构建一系列规则。 例如,它们通常用于保险承保和银行信贷承保(但也用于一些深奥的领域,如富士咖啡的咖啡烘焙或金宝罐头汤的汤准备)。
专家系统在一定程度上运行良好,易于理解。 然而,当规则的数量很大(通常超过几百条),规则开始相互冲突时,它们往往会崩溃。 如果是知识如果字段发生变化,更改规则将是困难和耗时的。
基于规则的系统自其早期全盛以来没有太大的改进,但保险和银行等大量使用这些系统的行业仍然需要新一代基于规则的技术。 研究人员和供应商已经开始讨论“自适应规则引擎”,引擎将基于新数据或规则引擎和机器学习的组合不断修改规则,但它们尚未被广泛使用。
06物理机器人
每年安装20多万台工业机器人,物理机器人是众所周知的。 在美国和ldquo;了解认知和研究调查中,32%的公司在一定程度上使用了物理机器人。 他们在工厂和仓库中进行起重、重新定位、焊接或组装产品等。 历史上,这些机器人在仔细的计算机程序控制下执行特定的任务。
然而,机器人越来越能够与人类一起工作,更容易训练,只是根据预定的任务移动机器人的部件。 他们也变得更加聪明,因为其他的人工智能能力被嵌入到他们的大脑和研发系统中。 随着时间的推移,我们在人工智能的其他领域看到的改进很可能被纳入物理机器人。
07机器人过程自动化
机器人过程自动化(RoboticProcessAutomation,RPA)技术就像人类用户在执行结构化数字任务时按照脚本或规则工作。 关于RPA是否属于人工智能/认知技术的集合,存在争论,因为因为它不是很聪明。 然而,由于RPA系统如此受欢迎、自动化和日益智能化,我认为它们是人工智能世界的一部分。
有些人称它们为数字劳动力和rdquo,与其他形式的人工智能相比,它们便宜、易于编程和透明。 您可以理解甚至开发RPA。 如果您可以操作鼠标,理解流程图,并理解一些if-then业务规则,这些系统也比其他方法更容易配置和实现,例如用编程语言开发自己的程序。
RPA并不真正涉及机器人,它只是服务器上的一个计算机程序。 它依赖于工作流程、业务规则和信息系统的集成和ldquo;表示层和rdquo;来作为系统的半智能用户工作。
有些人在电子表格中比较RPA和宏,但我不认为这是一个公平的比较,RPA可以执行更复杂的任务。还与业务流程管理(Business Process Management,BPM)工具进行了比较,该工具可能具有一些工作流功能,但通常旨在记录和分析业务流程,而不是实际自动化。
一些RPA系统已经具有一定的智能。 他们可以观察和研究人类同事的工作(例如。 回答常见的客户问题),然后模仿他们的行为。 另一些则将过程自动化与机器视觉相结合。 与物理机器人一样,RPA系统正在慢慢变得更加智能,其他类型的AI技术正在被用来指导他们的行为。
我分别描述这些技术,但在现实中,它们越来越结合和整合。 是的目前,商业决策者必须知道什么技术可以完成什么任务。
全球公司(Global Inc.)首席信息官克里希纳·内森(Krishna Nathan)指出,他2018年的主要优先事项之一是“帮助我的利益相关者了解人工智能可以和不能这样做,以便我们能够以正确的方式使用人工智能;。 也许在未来,这些技术将是混合的,以便这样的理解将不再是必要的,甚至是可行的。
作者:Thomas H.Davenport(Thomas H.Davenport),巴布森学院(Babson College)信息技术与管理杰出教授,曾获哈佛大学哲学博士学位,曾在哈佛商学院,芝加哥大学和波士顿大学任教。 曾任埃森哲战略变革研究所所长,他拥有广泛的研究领域,包括信息和知识管理、重组和信息技术在商业中的应用。
本摘要是由出版商授权的“数字时代的企业AI优势:IT巨人的业务实践”汇编而成。