轮廓

近年来,随着自然语言处理,计算机视觉等领域的人工智能快速发展,公众需要一个简单有效的指标,帮助确定系统的人工智能和整个高性能。人工智能发展现状。与此同时,良好的指标也可以在一个领域引发健康的可持续发展。
然而,传统的高性能计算机评估方法和系统与当前人工智能的性能并不完全一致。例如,Linpack是一种高性能的计算机双精度浮点计算性能基准评估程序,并且国际超级成本前500个列表根据临床值排名,典型的人工智能应用不需要双精度浮动观点。手术。大多数人工智能训练任务基于单精度浮点或半精密浮点数,原因是基于INT8。
对于大型人工智能,开发简单有效的指标和测试方法并不容易。首先,大多数单一人工智能训练任务(例如培训推荐的系统或图像分类的图像分类)无法计算总机的计算要求。许多人工智能应用,即使他们使用全机尺寸,训练时间和准确性也可能无法改善。其次,如果要测试手动智能群集计算机,则测试程序必须是可变的。首先,它必须清楚,可以任意调整哪种主流人工智能应用。最后,准确性的判断和计算是大规模人工智能评估和传统的基于高性能计算的评价之间的显着差异。是否需要使剩余的剩余量小于给定的标准,是衡量分数统计的准确性,同样需要清除。
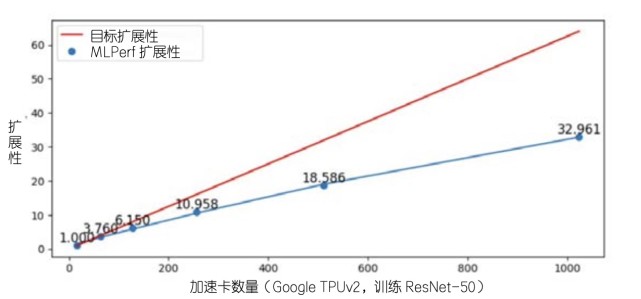
目前,主要公司,大学和相关组织在人工智能绩效基准领域有很多探索,并开发了各种参考评估程序,如Mlperf,小米的Mobileai长凳,百度公司的深井,中国人工智能产业发展联盟。 AIIA DNN基准和HPL-AI,基于双重精密延长螺旋更换为混合精度。但这些参考测试程序不会很好地解决上述问题。根据MLPERF发布的数据,MLPERF程序将在多TPU加速器卡的规模中下降或更大,并且在数千个TPU加速卡水平上达到评估系统的可扩展性瓶颈。该评估过程难以评估不同的系统。规模尺度差异的差异。
Mlperf延伸瓶颈
AIPERF设计目标和想法
AIPERF是清华大学设计的人工智能参考测试程序,具有设计目标:
统一分数
参考测试程序应将分数作为评估指标报告,以评估群集系统。使用一个而不是多个分数来轻松比较不同的机器,并促进公众的宣传。此外,分数应随着人工智能计算群集的规模增加线性生长,并且可以准确地评估不同系统中规模的差异。
2.可变问题量表
人工智能计算集群通常具有不同的系统规模,节点数量的差异反射,加速器数量,加速器类型,内存大小和其他指示器。因此,为了适应各种尺寸的高性能计算群集,预期的人工智能参考测试程序应该能够通过问题的大小来适应簇大小的大小。使用人工智能计算计算资源以反映其实力。
3.有实际的人工智能
用人工智能计算,如神经网络运营,是人工智能参考测试程序和传统的高性能电脑参考测试的一个重要区别,也是检测簇人工智能的核心。人工智能参考测试程序应基于当前流行的人工智能应用。
4.评估计划包含必要的多机器通信
网络通信是人工智能计算集群设计的主要指标之一,也是其巨大计算能力的重要组成部分。用于高性能计算集群的人工智能参考测试程序应包括必要的多机通信,从而使用网络通信性能作为最终性能的影响因素之一。同时,参考测试程序中的多机通信模式应该具有典型的表示。