到处都是垃圾:人工智能太缺乏高质量的数据,

阅读:来源|核心阅读地图来源:在一定程度上,人工智能已经超越了我们过去最大胆的想象;但在实践中,Siri甚至不能告诉用户今天的天气如何。 有什么问题吗? 创建高质量的数据库来训练和测量我们的模型仍然是一项极其困难的任务。 我们应该可以收集两万。。。 源|一天内核心阅读

资料来源:光彩照人

在某种程度上,人工智能已经超越了我们过去最大胆的想象;但实际上,Siri甚至不能告诉用户今天的天气如何。
有什么问题吗? 创建高质量的数据库来训练和测量我们的模型仍然是一项极其困难的任务。 我们应该能够在一天内收集20000个标签来训练Reddit分类器,但是我们等待了三个月,得到了一个充满垃圾邮件的训练集。
《纽约时报》称,四年前,AlphaGo击败了世界围棋专家,大型科技公司为每一家他们能接触到的机器学习初创企业购买了人才; 计算机技术
深层思维在2016年开始建立一个人工智能来玩星际争霸2,到2019年底,人工智能项目“阿尔法星”(AlphaStar&rdquo)已经取得了巨大的成就。
看来几年后,Alexa将占据我们的家园,Netflix将比我们的朋友提出更好的电影建议。
在那之后发生了什么?
更快的GPU放弃了训练神经网络消费,并允许不断增长的模型被训练。 新工具使基础设施更容易工作。
还开发了新的神经网络结构,可以学习运行更多的主观任务。 例如,Open Ai GPT-3模式是一种语言生产者,可以撰写博客文章,并从黑客新闻网站获取标题。
一篇关于生产力GPT-3的博客文章成为黑客新闻的头条。
那么改革是在哪里进行的呢?
那么人工智能为什么不占领世界呢? 为什么人们可以用GPT-3生成博客文章,但社交媒体公司很难从订阅者中删除煽动性内容? 为什么会有超人星际争霸算法,但是电商还在推荐我再买一个呕吐司机? 为什么模型可以合成逼真的图片(和电影)但不能被识别?
模型正在进展中,数据仍处于停滞状态。模型是在数据集上训练的,数据集仍然有错误,并且很少与创建者真正想要表达的内容一致。
当前数据发生了什么? 来垃圾,去垃圾
在某些情况下,数据是基于类(如链接和用户协议)对代理进行培训的。
例如,社交媒体推文没有经过培训以提供最佳的用户体验;相反,它们只是充分利用链接和协议,这是获取数据的最简单方法。
但点赞数量与数量无关。 骇人听闻的阴谋论非常引人注目,但你真的想在你的推特上看到它们吗? 这种不匹配导致了许多意想不到的副作用,包括点击诱饵的激增、广泛的政治虚假信息和广泛的恶意、煽动性内容。
在其他时候,模型是在这样的数据集上训练的:由非母语使用者或知道低质量结果的人训练的工作人员远远没有被检测到,而是创建数据集。 取以下推文:
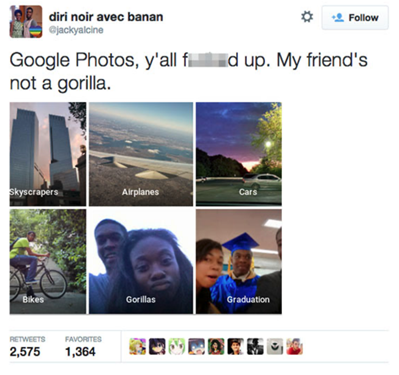
一个典型的标记识别“婊子”,“他妈的”和“屎”并将这条推特标记为有害的,无论虐待是否基于积极、向上的态度。 这在训练集中发生了无数次。 数据定义模型。 如果数据被错误标记为垃圾,没有机器学习专家可以防止模型同样无用。
我们需要什么样的进步?
数据集问题造成了很多问题。
当面临运行不良的模型时,工程师花了几个月的时间来修复产品特性和新算法,而不知道它们的数据中存在问题。 本来应该用来凝聚感情和友谊的算法,相反,会带来炽热的情绪和愤怒的评论。 如何解决这些问题?
熟练和高质量的标记,理解你试图解决的问题
虽然AI系统越来越复杂,但我们需要先进而巧妙的人类标记系统来教授和测量它们的性能。 想想那些了解世界的模型,足以对误导性信息进行分类,或者增加时间而不是点击的算法。
这种复杂性不会因为使用低技能工人而增加。 为了让我们的机器理解仇恨言论和识别算法偏见,我们需要高质量的标签力量,他们自己也理解这些问题。
空间供机器学习组和识别器进行交流
机器学习模型不断变化。 今天的垃圾信息明天可能不一样,我们永远无法掌握密码的每一个角落。
就像制造产品是一种用途一样与工程师之间的反馈驱动过程一样,数据集的创建也应该如此。 在数一幅画中的面孔时,卡通人物是否计数? 在标记仇恨言论时,引号在哪里? 标记在浏览数千个示例后发现了歧义和洞察力,为了最大限度地提高数据质量,我们需要双方进行沟通。
目标功能符合人类价值观
模型通常被训练在数据集上,这些数据集只是他们真正目标的近似,导致意想不到的分歧。
例如,在关于人工智能安全的辩论中,人们担心机器智能发展到威胁世界的程度。 其他人反驳说,这是一个遥远的未来的问题,然而,看看当今技术平台面临的最大问题,它不是已经发生了吗?
例如,Facebook的使命不是获得喜欢的东西,而是让我们与朋友和家人联系起来。但通过训练他们的模型来增加偏好和互动,他们学会传播具有高度吸引力的内容,但也可能是有害的和误导的。
如果Facebook能将人类价值观注入他们的培训目标? 这不是幻想:谷歌搜索在其实验中使用了人类评估,我们正在构建的人工智能系统致力于这样做。
一个数据驱动的人工智能未来
在核心,机器学习是教计算机以我们想要的方式工作,我们通过展示积极的例子来实现我们的目标。 那么为了建立一个高质量的模型,机器学习工程师需要掌握的最重要的技能不应该是建立一个高质量的数据集,并确保它们与手头的问题相匹配吗?
最后,我们担心人工智能是否能满足人类的需求,而不是它是否超过人类的基准。
如果你在这里处理内容规则,您的数据集是否检测到恶意语音,还是它也捕获积极的、令人振奋的言语虐待?
如果您正在构建下一代搜索和推荐系统,您的数据集是设置模型的相关性和质量,还是误导和吸引点击是很吸引人的?
创建数据集不是学校里教的东西,花了多年研究算法的工程师很容易专注于arXiv中最花哨的模型。 但如果我们想要人工智能解决自己的实际需求,就需要对定义模型的数据集进行深入的思考,并赋予它们一定的人文色彩。
源|核心阅读编译|欧舒曼周婷
关于腾讯AI加速器
腾讯AI加速器是腾讯行业加速器的重要组成部分。依托腾讯AI实验室矩阵核心技术,腾讯云平台,计算能力以及合作伙伴丰富的应用场景,为选定的课程,技术,资本,生态,品牌等层面的项目提供支持。 并与入选项目一起打造行业解决方案,推动AI技术在行业的应用落地。
前两个AI加速器期间,从全球2000项目中筛选出65个项目,整体估值662亿,总融资达70亿,70%的项目完成新一轮融资;其中腾讯投资乐聚机器人,工匠社会机器人,VersaMacaron播放图片,并形成行业解决方案50。
162019年8月,腾讯AI加速器三期上市。 从1500个申请人中脱颖而出的TOP30项目,验收率仅为2%,第三阶段项目总估值超过200亿。 该项目的重点是金融、教育、安全、工业、机器人、物联网、云计算、5G等。 精选腾讯AI加速器第三期,意义正式成为腾讯智慧产业生态合作伙伴,将与腾讯各智慧产业业务深度结合。