寰球人为智能振奋毕竟到了什么程度
根源:第一财政和经济
对于人为智能在此刻科学技术界的振奋程度,学术界、财产界和媒介界大概会有不同的管见。我常常听到的一个说法是:此刻鉴于大数据与深度进修的人为智能是一种实足别致的本领样式,它的展现不妨所有地变换将来人类的社会样式,由于它不妨自决进行“进修”,由此洪量代替人类血汗。
我觉得这边有两个曲解:第一,深度进修并不是新本领;第二,深度进修本领所波及的“进修”与人类的进修并不是一回事,由于它不能真实“深度”地舆解它所面临的消息。
深度进修不是新本领
从本领史角度看,深度进修本领的前身,本来即是在20世纪80岁月就仍旧嘈杂过一阵子的“人为神经元搜集”本领(也叫“贯穿主义”本领)。
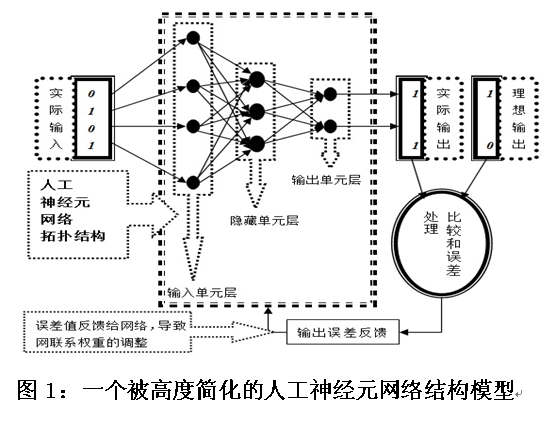
该本领的本质,是用数学建立模型的方法创造出一个简略的人为神经元搜集构造,而一个典范的此类构造普遍包括三层:输出单位层、中央单位层与输入单位层。输出单位层从外界博得消息之后,按照每个单位内置的集聚算法与激励函数,“确定”能否要向中央单位层发送进一步的数据消息,其进程正如人类神经元在接受其他神经元送来的电脉冲之后,能按照自己细胞核内电势位的变革来“确定”能否要向其余的神经元寄递电脉冲。
须要提防的是,不管所有体例所实行的完全工作是对于图像辨别保持天然谈话处置,不过从体例中单个计划单位自己的运作状况动身,查看者是无从领会关系完全工作的本质的。毋宁说,所有体例本来是以“化整为零”的办法,将宏观层面上的辨别工作领略为了体例构成构件之间的微观消息传播振动,并经过这些微观消息传播振动所展现出来的大趋向,来模仿人类心智在标记层面上所进行的消息处置过程。
工程师安排体例的微观消息传播振动之趋向的基础本领如下:先是让体例对输出消息进行随机处置,而后将处置截止与理念处置截止进行比对。若二者符合度不佳,则体例触发自带的“反向传递算法”来安排体例内各个计划单位之间的接洽权重,使得体例给出的输入与前一次输入不同。两个单位之间的接洽权重越大,二者之间就越大概爆发“共激励”局面,反之亦然。而后,体例再次比对本质输入与理念输入,即使二者符合度仍旧不佳,则体例再次启用反向传递算法,直至本质输入与理念输入彼此符合为止。
实行此番演练进程的体例,除了不妨对演练样品进行精确的语义归类除外,普遍也能对那些与演练样品比拟逼近的输出消息进行相对准确的语义归类。比方,即使一个体例已被演练得不妨辨别既有相影片仓库里的哪些相片是张三的脸,那么,固然是一张从未加入相影片仓库的新的张三像片,也不妨被体例赶快辨别为张三的脸。
即使读者对于上述本领刻画还似懂非懂,不妨经过底下这个比如来进一步领会人为神经元搜集本领的运作机理。假如一个不懂汉语的番邦人跑到少林寺学技击,师生之间的熏染振动该怎样发展?有两种情景:第一种情景是,二者之间不妨进行谈话调换(番邦人懂汉语大概少林寺师父懂外语),如许一来,师父就不妨直接经过“给出规则”的办法熏染他的番邦门徒。这种培植本领,或可委屈类比鉴于规则的人为智能路数。
另一种情景是,师父与门徒谈话实足不通,在这种情景下,弟子又该怎样学武呢?只有靠如下方法:门徒先查看师父的办法,而后跟着学,师父则经过大略的肢体调换来报告门徒,这个办法学得对不对(比方,即使对,师父就浅笑;即使不对,师父则当头棒喝门徒)。从而,即使师父确定了门徒的某个办法,门徒就会记取这个办法,贯穿往放学;即使不对,门徒就只好去商量本人何处错了,并按照这种商量给出一个新办法,并贯穿等候师父的反应,直到师父最后合意为止。很明显,如许的技击进修功效是特出低的,由于门徒在胡猜本人的办法何处堕落时会滥用洪量的功夫。但“胡猜”二字凑巧切中了人为神经元搜集运作的本质。概而言之,如许的人为智能体例本来并不领会本人获得的输出消息毕竟表示着什么——换言之,此体例的安排者并不能与体例进行标记层面上的调换,正如在前方的例子中等师范学院父是无法与门徒进行谈话调换一律。而这种低效进修的“低效性”之以是在计划机何处不妨获得忍耐,则缘于计划机比拟于天然人而言的一个宏大上风:计划机不妨在很短的物理功夫内进行海量次数的“胡猜”,并由此抉择出一个比拟精确的解。一旦看领会了内里的机理,咱们就不难创造:人为神经元搜集的处事道理本来是特出蠢笨的。
“深度进修”该当是“深层进修”
那么,何以“神经元搜集本领”此刻又有了“深度进修”这个后继者呢?这个新花样又是啥道理呢?
不得不供认,“深度进修”是一个带有迷惘性的花样,由于它会诱使很多生手觉得人为智能体例仍旧不妨像人类那样“深度地”领会本人的进修实质了。但如实情景是:按照人类的“领会”规范,如许的体例对原始消息最浮浅的领会也无法到达。
为了遏止此类曲解,笔者比拟扶助将“深度进修”称为“深层进修”。由于该词的英文原文“deeplearning”本领的真实含意,即是将保守的人为神经元搜集进行本领晋级,即大大减少其湮没单位层的数目。如许做的长处,是不妨增大所有体例的消息处置机制的精致度,使得更多的东西特性不妨在更多的中央层中获得安置。
比方,在人脸识其他深度进修体例中,更多的中央档次不妨更为精致地处置低级像素、色块边际、线条拉拢、五官表面等处在不同抽象层面上的特性。如许的精致化处购置法固然不妨大大普及所有体例的辨别本领。
但须要看到,由此类“深度”化诉讼要求所带来的所有体例的数学搀杂性与数据的百般性,天然会对计划机硬件以及演练用的数据量提出很高的诉讼要求。这也就表明了何以深度进修本领在21世纪后才渐渐时髦,恰是迩来十几年此后计划机范围内蒸蒸日上的硬件振奋,以及互联网普遍所带来的宏大数据量,才为深度进修本领的落地着花供给了基础保护。
但有两个瓶颈遏制了神经元搜集-深度进修本领进一步“智能化”:
第一,一旦体例过程演练而变得抑制了,那么体例的进修本领就低沉了,也即是说,体例无法按照新的输出安排权重。这可不是咱们的最终理念。咱们的理念是:假设因为演练样品库自己的控制性,搜集过早地抑制了,那么面临新样品时,它仍旧不妨自决地订正从来产生的输出-输入映照接洽,并使得这种订正不妨兼顾旧有的汗青和新展现的数据。但现有本领无法扶助这个看似洪大的本领构想。安排者暂时所不妨做的,即是把体例的汗青常识归零,把新的样品归入样品库,而后从新发端演练。在这边咱们无疑又一次看到了让人毛骨悚然的“西西弗斯轮回”。
第二,正如前方的例子所展示给咱们的,在神经元搜集-深度进修形式识其他进程中,安排者的很多心力都耗费在对于原始样品的特性索取上。很明显,同样的原始样品会在不同的安排者何处具备不同的特性索取形式,而这又会启发不同的神经元搜集-深度进修建立模型目的。对人类编制程序员来说,这恰是展现本人创作性的好机会,但对于体例本人来说,这即是褫夺了它自己进行创作性振动的机会。试想:一个被如许安排出来的神经元搜集-深度进修构造,不妨本人查看原始样品,找到符合的特性索取形式,并安排出本人的拓扑学构造吗?可见很难,由于这犹如诉讼要求该构造背地有一个元构造,不妨对该构造本人给出反省性的表征。对于这个元构造该当怎样被步调化,咱们暂时仍旧是一团雾水——由于实行这个元构造功效的,恰是咱们人类本人。让人悲观的是,固然深度进修本领带有这些基础缺点,但暂时的合流人为智能界仍旧被“洗脑”,觉得深度进修本领就仍旧即是人为智能的十足。一种鉴于少量据,更加精巧、更为通用的人为智能本领,明显还须要人们加入更多的心力。从纯学术角度看,咱们离这个目的还很远。